توجد الكثير من الجهات التي تتعامل مع أعداد كبيرة من الوثائق والمستندات المخزنة على شكل صور، والتي
ترغب الجهة في الاستفادة من البيانات الموجودة في تلك الصور وتحويلها إلى بيانات رقمية. في هذا المقال
سنتعرف على المراحل والخطوات التقنية المبنية على علم معالجة الصور (Image Processing) باستخدام الذكاء
الإصطناعي (AI) لتحويل النصوص الموجودة في الصور إلى بيانات رقمية. تم تطبيق هذه المراحل والخطوات في
أحد مشاريعنا على أعداد كبيرة من جوازات السفر، وكانت نسبة دقة البيانات تتراوح بين 96% و 99%.
المرحلتين الأولى والثانية إلزامية والمرحلة الأخيرة اختيارية، في كل خطوة من خطوات المراحل سيتم ذكر
اكثر من تقنية أو خوارزم لإعطاء القارئ عدة خيارات يمكن الاختيار بينها أو يمكن استخدامها بشكل متداخل
لرفع جودة العمل.
المرحلة الأولى هي المعالجة الأولية لتحسين جودة الصورة حيث ينتج
عنها صورة بدون
ضوضاء ومستقيمة وذات
حواف واضحة ومحدد بها منطقة النصوص وتتكون من الخطوات التالية:
- قراءة الصورة وتحويلها إلى مصفوفة رقمية
- تحويل الصور الملونة إلى التدرج الرمادي (Grayscale) لتسهيل وتقليل البيانات المراد معالجتها
وتبسيط
التحليل البصري للصورة، يتم إنجاز هذه الخطوة باستخدام دمج قنوات الألوان والتصفية (Filtering)
- تصحيح الميل (Skew Correction) بعض الصور تكون ملتقطة بشكل مائل أو منحرف يجعل من الصعب على
أدوات
الذكاء الاصطناعي التعرف على النصوص ومعالجتها، ولذا يجب تصحيح ميل الصورة وتعديله. من أشهر
تقنيات
التصحيح في مجال معالجة الصور (Hough Line Transform) لاكتشاف الخطوط وتصحيح الميل، وتحليل
الإسقاط
(Projection Profile Analysis)، وتحليل المناطق المحيطة (Contours Detection)
- تصحيح الإضاءة (Illumination Correction) بعض الصور يتم التقاطها في مكان ضعيف الإضاءة أو مكان
به
إضاءة غير مستوية ماينتج عنه صورة به بقع ضوئية أو مناطق ذات إضاءات مختلفة ممايجعل تحليل النص
باستخدام خوازم واحد مهمة صعبة. بشكل عام الصور الملتقطة بالكاميرات غير احترافية غالبا ما
تتأثر
بظلال أو أضواء زائدة بخلاف الصور الممسوحة بالماسحات الضوئية فهي تكون ذات مستوى واحد من
الإضاءة.
من الطرق المستخدمة في تصحيح الإضاءة أثناء معالجة الصور حساب الخلفية (Background Estimation)
حيث
يتم حساب مكونات الخلفية ذات الإضاءة غير المنتظمة ثم طرحها من الصورة أو تسوية الإضاءة
(Illumination Normalization)
- إزالة الضوضاء والتشويش في الصورة (Noise Removal) بعض الصور قد يتم التقاطها وبها نقاط أو خطوط
أو
أشكال أخرى ليست من أصل الصورة بسبب عدم نظافة العدسة أو الماسح الضوئي أو البيئة المحيطة
بالصورة
أو وجود غبار على الصورة ذاتها. وجود ضوضاء أو تشويش في الصورة قد يسبب قراءة النص بطريقة غير
صحيحة، فوجود خط زائد على سبيل المثال قد يحول حرف إلى حرف آخر. يمكن إزالة الضوضاء باستخدام
(Gaussian Blur) أو (Bilateral Filter) أو (Median Filter) أو التحليل الترددي (Frequency
Domain
Filtering) أو تحليل الموجات (Wavelet Transform)
- تحويل الصورة إلى اللون الأسود والأبيض (Binarization) لتحسين التعرف على النصوص وتخفيض الحجم.
من
أشهر تقنيات التحويل (Thresholding) و (Adaptive Thresholding)
- تحسين الحواف (Edge Enhancement) وذلك لجعل النصوص والخطوط أكثر وضوحاً. يمكن انجاز هذه الخطوة
باستخدام (Canny Edge Detection)
- تصحيح التشوهات الهندسية (Geometric Corrections) في حال كانت الصورة أو أحد أجزائها منحنية أو
تحتوي على انحرافات، فيمكن تعديل هذه الانحراف الجزئي باستخدام (Perspective Transformation)
- تحديد المناطق المهمة (ROI-Region of Interest)، في مثالنا الحالي الخاص بجوازات السفر المنطقة
المهمة هي المنطقة التي بها حروف مكتوبة، يتم تحديد هذه المنطقة باستخدام خوارزميات كشف
الكائنات
مثل (YOLO) أو (Faster R-CNN)
المرحلة الثانية هي مرحلة استخراج النصوص من مناطق الـ (ROI)
باستخدام تقنية التعرف الضوئي على الحروف (Optical Character Recognition-OCR) وتشمل الخطوات التالية
وذلك بهدف رفع دقة التعرف على النصوص:
- تحديد الحروف (Character Recognition) عن طريق تحليل الأنماط (Pattern Matching) ومقارنتها
بقواعد بيانات أنماط الأحرف
- التعرف القائم على المكونات (Feature Extraction) تحليل سمات الحرف مثل الانحناءات والخطوط
المستقيمة
- الشبكات العصبية (Neural Networks) استخدام نماذج تعلم الآلة لفهم شكل الحرف بناءً على التدريب
المسبق
- التعلم العميق (Deep Learning)
المرحلة الثالثة ويتم فيها تحليل النصوص وتصحيحها
وتصنيفها. هذه المرحلة اختيارية وتتم بناء على طلب المستخدم حيث يفضل بعض المستخدمين عدم تعديل الأخطاء
الموجودة في النصوص والاحتفاظ بها كما هي. تشمل هذه المرحلة الخطوات التالية:
تحسين النتيجة النهائية من خلال التدقيق الإملائي بمقارنة النص المتعرف عليه مع قواميس اللغة. أو
التحسين من خلال التعرف السياقي حيث يتم تصحيح الأخطاء بناء على سياق الجملة
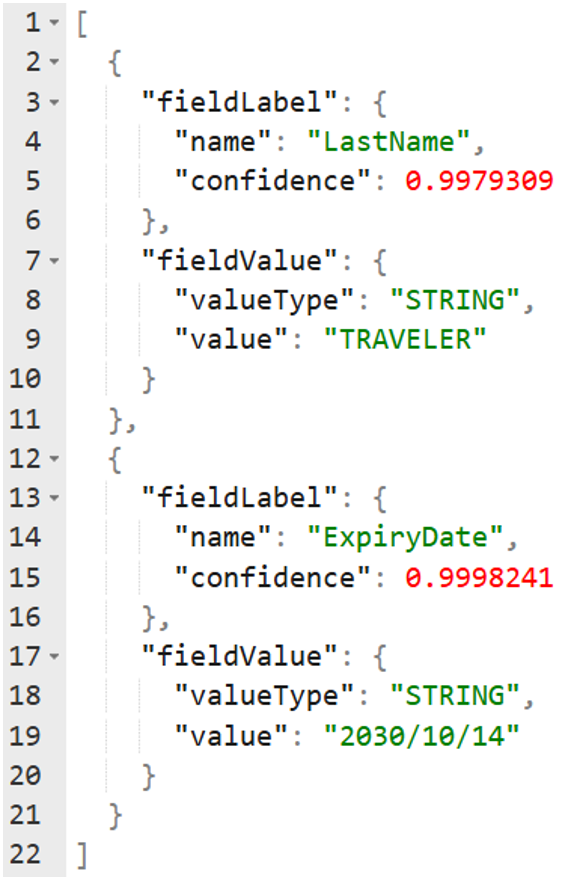
تكون المخرجات النهائية للمراحلة السابقة على صورة بيانات (JSON) كما في الصورة التالية. نلاحظ أن في
حالة صورة جواز السفر، يتم استخراج البيانات في صورة مصفوفة. بحيث يحتوي الجزء الأول منها على نوع
البيان كالاسم الأخير (LastName) أو تاريخ الانتهاء (ExpiryDate) ومستوى الدقة في التعرف على النص وهي
في هذه الحالة (99.79% و 99.98%). والجزء الثاني يحتوي على النص المستخرج من الصورة ونوعه